安宅和人が語るAI×データ活用の過去と未来 ビジネスパーソンに求められるマインドとは?




これまでヤフーでは、日本最大級のポータルサイトYahoo! JAPANに匿名化され、蓄積されたさまざまなデータを分析・活用し、「データの持つ力と面白さ」を伝える目的で「ビッグデータレポート」を定期的に発信してきました。
新生LINEヤフーとなり、ビッグデータの可能性がさらに広がった今、このレポートはどう進化していくのか。AI時代のビジネスパーソンに求められるスキルやマインドとは? LINEヤフーのシニアストラテジストで、ビッグデータレポートチーム(マルチデータ研究室)を長年率いてきた安宅和人に話を聞きました。
生成AIがもたらすビジネス環境の変化、AI時代に求められるマインドなど、こちらからハイライト動画もご覧いただけます。

- 安宅 和人(あたか かずと)
- マッキンゼーにて11年間、幅広い商品・事業開発、ブランド再生に携わった後、 2008年からヤフー、2012年より10年間CSOを務め、2022年よりZホールディングス (現LINEヤフー株式会社)シニアストラテジスト。2016年より慶應義塾SFCで教え、2018年秋より環境情報学部教授。データサイエンティスト協会理事・スキル定義委員長(発起メンバー)。一般社団法人 残すに値する未来 代表。科学技術及びデータ×AIに関する公的検討に多く携わる。イェール大学脳神経科学PhD。著書に『イシューからはじめよ』(英治出版)、『シン・ニホン』(NewsPicks)、『ビッグデータ探偵団』(講談社現代新書)など。
ビッグデータレポートがスタートした経緯
――安宅さん率いるチームがビッグデータレポートを出すことになった経緯とは?
ヤフーがCEO宮坂さん(現東京都副知事)・COO川邊さん(現LINEヤフー会長)の体制になった2012年の春からCSO(チーフストラテジーオフィサー)となり、前体制下でも担当してきた事業戦略、全社事業開発、社長室的な機能、データインサイト& 市場リサーチ機能に加え、データ部門や研究所といった研究開発機能も統括するようになりました。
ちょうどビッグデータに対する社会の関心が全世界的に急激に高まり、問い合わせや登壇依頼が急増するようになった頃です。当時、ビッグデータを実際に持ち、日常的に使っている会社が国内に数えるほどしかなかったからです。
その接点の中でヤフーのシニアマネジメントメンバーの僕らが強く感じていたのは、「ビッグデータに対する社会の関心は高まっているものの、社会的にはビッグデータの可能性や力もわからないまま、目に見えない恐怖みたいなものが増幅している」ということでした。新しいリスクに対する啓発と備えは確かに重要だが、世界がビッグデータ、計算機、アルゴリズムのかけ合わせにより歴史的な進化をする中、この力と価値を知らないまま距離をおいておくと、ただでさえ周回遅れの日本はまずい状況になると。
この問題意識を受け「ビッグデータの持つ力と面白さを訴える取り組みをできないか」と、12年末に始めたのがYahoo! JAPANビッグデータレポートでした。
――どのような感じで立ち上げましたか?
12年末、衆院選というちょうどわかりやすいテーマがあったこともあり、なにかビッグデータから見えるといいよね、という話を川邊さんとしたのがきっかけです。僕の部隊で興味がある人はいないかと声をかけると、ありがたいことに数名が手を挙げてくれました。とはいえ、すでに12月も半ばだったこと、相当忙しい面々ばかりで、彼らも持っている時間のせいぜい2〜3割ぐらいしか使えなかったこともあり、相当イシュードリブンに掘ってもらいました。具体的にはネット上の注目とリアルの投票行動の関係性について仮説的なストーリーとブランクチャートを僕が描き、それをベースに数日でさっと見てもらった感じです。
すると、ほとんどドンピシャで、ネット上の興味や関心はリアルとは異質という当時の通念とは大きく異なり、ネット上の注目度や関心内容とリアルな投票行動には相当に強い関係性があることがわかりました。それどころか、関心の種類によっては当落すらわかりそうだったのです。これをその後、わずか数日でレポートとしてまとめて年末に出したのが第一号でした(※)。
※「衆議院議員選挙とYahoo!検索の驚くべき関係」(2012年12月28日)
当然ヤフーのトップページやYahoo!ニュースにリンクを張ったわけでもない、まだ世に出たばかりのたった1本の記事が、ソーシャルメディアやジャーナリズム界隈で想定の範囲外のレベルでバズり、新聞などからも随分な数の取材依頼が来ました。
この勢いを受け、兼務のプロ集団による組織をCSO直下に正式につくることにした感じです。とはいえ、これも僕が担当していた研究者/サイエンティストが集まるYahoo! JAPAN研究所(現 LINEヤフー研究所)があるので、このビッグデータレポートチームは組織的には当初「生活研」と呼ぶことになりました(後にマルチデータ研究室と改称)。
これまで大きく話題になったものとしては、国政選挙予測(2013年 参院選で史上最高の96%の予測に成功)、景気予測(内閣府の景気一致指標を相当精度で発表の一カ月前に予測。一週間ごとの値も算出)、インフル蔓延状況の毎週の予測(国の発表の一週間以上前にナウキャストし、地域別に流行、蔓延、峠を越える、終息などのフェーズも可視化)、2つの日本(日本における東京の異質性をビッグデータ的に示した)などがあります。
――どんなメンバーが「ビッグデータレポートチーム」には集まっているのでしょうか?
ベースは設立当時の可視化推進(market insight)部門のデータインサイト系の人たち、データソリューション(DS)本部でデータから人にわかるインサイトを出すことに長けていた人たち、そして研究所の中で、学会やカンファレンスとは別に、こういう一般向けの打ち出しにも興味を持ってくれた人たちです。データインサイトというのはシリコンバレー系の会社ではどのようなサービスにも数名いるのですが、データマートやデータウェアハウスから直接広範で複雑なビッグデータを取り込み、ビジネス的に必要な集計と解析を行う人たちです。
編集長を務める池宮伸次さんは市場観察センスのずば抜けたデータ使いですが、元編集者で素晴らしい書き手です。選挙予測や芸能という人気系を中心に活動してきた阪上恵理さんはデータインサイトのプロです。彼女以上にビッグデータに基づき選挙予測をやってきた人はいないのではないかと思います。位置データの世界的な研究者の坪内孝太さんは福井の谷あいから参加。僕らのサイエンス的なブレーンですが景気予測や位置情報データをつかった隠れ避難所など数多くのレポートに携わってきました。景気に加えて、母の視点で子育て周りなどで渋いレポートを出していただいてきた稲葉真裕さんはデータアナリストです。選挙予測など数多くのレポートに携わった立ち上げメンバーの大瀧直子さんは可視化と分析のプロ。最近はデザイナーの谷本真帆さん、コマース系のエンジニアの内藤秀彦さんのお二人も若手コアメンバーでチームに活力を入れてもらっています。ちなみにこの面々には慶應SFCでのデータドリブン講義(Yahoo! JAPAN寄附講座として設立)にも力強く参加してもらっており、本当に頼りにしています。
なお、先ほど少し触れましたが、このチームには立ち上げ当初から誰も専任はいません。あくまで本物のプロが部活、余業的にやるというのが基本です。メンバーは本業に支障がない程度に、ベストエフォート(最大限の努力)でやるスタンスです。毎月、無理やり出すこともしません。
だからこそ、面白いものができるし、これだけ続いているのかなと思います。毎月の定例で企画が上がってきたら、ビッグデータレポートの趣旨的にハマるようにテーマを磨き直しています。立ち上げ以来ずっと、データの持つ価値なり面白さを伝えられるものであるかどうか、を最も大切にしています。
ちなみに、僕らは常にメンバーを募集しています。世の中の多くの方にデータの力と面白さを届けることに興味がある、一緒にやりたいという方々はぜひ手を挙げて、チームの誰かにぜひ声かけてほしいですね。データビジュアライゼーションといって、大量のデータを可視化する取り組みはかつてそれなりにやりましたが、もっと模索したいのでこれらを探求したいデザイナー系の方々も超ウエルカムです。

データを取り巻く環境の変化
――ビッグデータレポートの取り組みが始まって約11年ですが、どのような変化があったでしょうか?
一言で言って激変ですね。2012~13年は明らかにビッグデータブームでした。「ビッグデータというビッグウエーブが来る!」という期待と不安が入り混じった沸き立つ感じがいたるところにありました。データサイエンティストが最もセクシーな職業になる、という言葉が出てきたのもこのあたりでした。
一方で、このままではデータ×AI人材が劇的に足りなくなるのは明らかで(僕らの会社としてももっともっとほしかった)、政府の方々に働きかけるだけでなく、それでは間に合わないので、産学の有志でデータサイエンティスト協会を設立し、必要な人材やスキルについての議論をし始めたのもその頃です(2013年5月に設立)。
2012年に重大な変化が起き、ディープラーニング(深層学習/DL)と呼ばれているものが唐突に従来型の機械学習では出ないような性能を出し始めました。最初は画像認識でした。2014年後半〜15年にはなにか途方もないことが起きているらしいと、世の中的にもAIに対する関心が急速に高まりました。いわゆるAIブームです。DLを実装した世界最初の本格的なアプリ Googleフォトが出たのは2015年の5月です。
国家としても「これは本当に重大だ」となって、「ビッグデータ時代に即した人材を育成しなければいけない」という集中議論が行われたのが15年の春でした。
――安宅さんは数えきれない公職についていますが、どんな議論がありましたか?
よく覚えているのが、その2015年の情報・システム研究機構(ROIS)&文部科学省でのビッグデータ時代の人材育成に関する集中検討です。
(参考)
ビッグデータの利活用のための専門人材育成について
(ROISの報告資料 )
(文部科学省説明資料)
今から考えると歴史的な検討だったのですが、僕は「データ×AIについてのリテラシーは多くの人に必須の時代に突入する。あらゆる産業が影響を受けるので、文理、専門を問わず、高等教育を受ける大半の人たちに新しい読み書きそろばんとして与える必要がある。その1割程度を専門人材に、そのまた1割程度をリーダー層に育てるべきだ」と三層構造の人材育成を提言しました。
これに対しては、実行性に対する困難を感じた文科省の方々から相当の抵抗がありました。「(高等教育を受ける人の大半にデータ×AI時代に即したリテラシー教育をやるなんて)何を言っているのかわかっているんですか? 教える人はどこにいるんですか? 毎年2000人程度育てるじゃダメなんですか? それだけ大量の人を育てたときに社会は受け入れてくれるんですか?」と。
僕は「これは本質的な変化であり、僕らの子や孫たちを路頭に迷わせたくなかったらやるべきだ。明治時代にさまざまな学校を作ったときと似たような話であり、人がいなければ国外から連れて来ればよい。いずれこれらの素養を持たない人をさまざまな会社は受け入れなくなるのでその方々の雇用は心配する必要はない。裾野の広さがリーダー層を育てる」と訴えました。
喧々諤々でしたが、この検討以外でもさまざまなところで力を合わせて訴え続けた結果、結局それが受け入れられて、2017〜18年頃、必須化の方針が決まりました。これを受け2019〜20年頃、国の数理/データサイエンス/AI教育のモデルカリキュラムの作成が行われ、これらのプログラムを実施している大学の認定制度もできました。カリキュラム立ち上げは委員、認定制度立ち上げは副座長として関わりました。別々の出自である統計数理系の方々、情報科学系の方々、計算機科学系の方々、これらを統合して使うデータ系の方々の会話の困難が相当にあったのを覚えています。
他にも人工知能産業化ロードマップの策定(国の最初のAI戦略立案)など政府のさまざまな委員をやってきましたが、その間に、今で言う生成AIに連なる大きな変化がありました。ディープフェイク問題の出現に代表されるような、圧倒的なレベルで、目で見て分かるぐらいの、今までではあり得なかったサービスがいくつか登場し始めたのです。
参考)この10年の概観
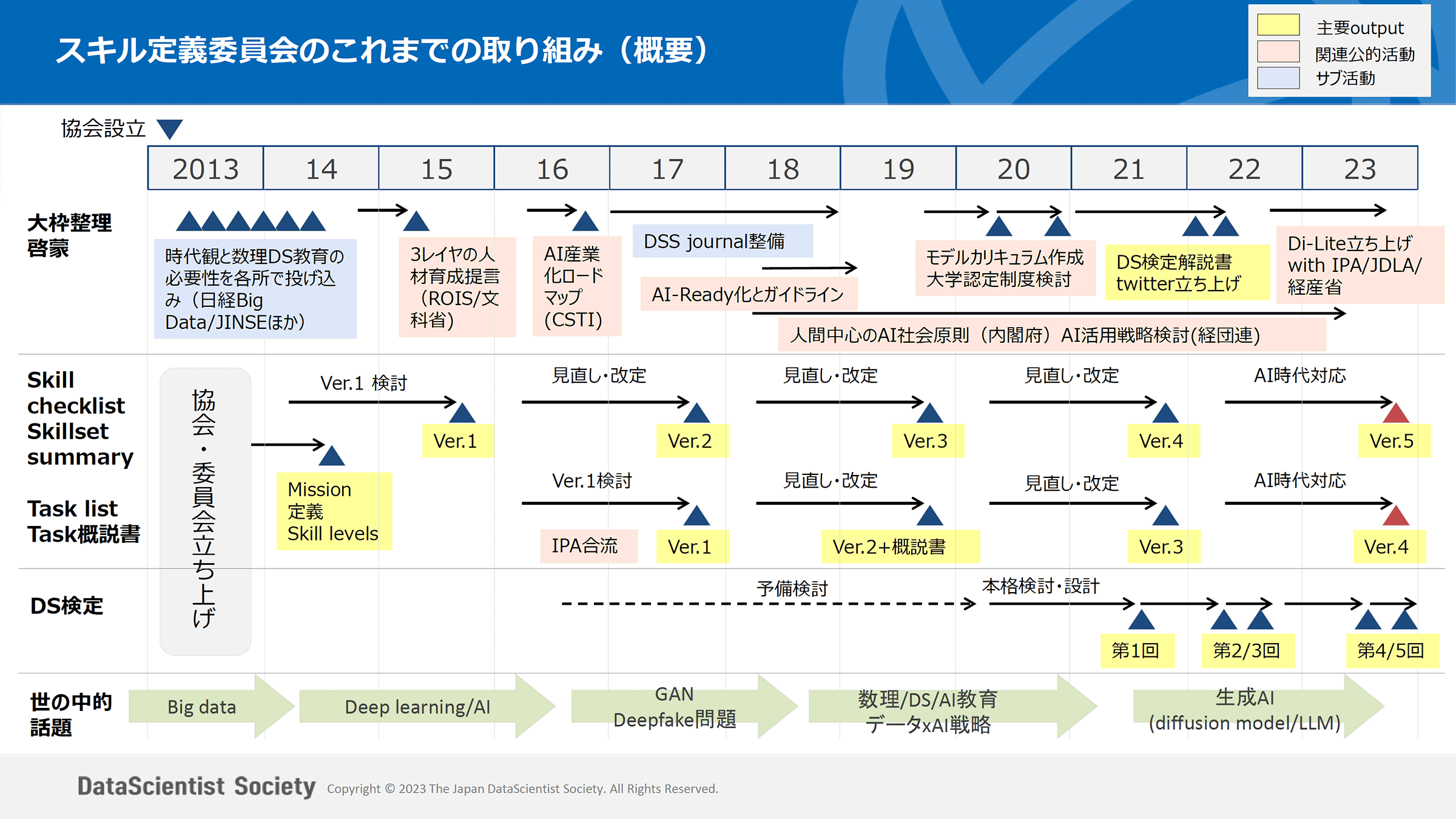
データサイエンティスト協会 スキル定義委員会発表資料(2023年10月20日)より
――生成系AIの登場、10年ほどの変化を踏まえ、この先をどのように捉えていますか?
この変化があまりにも速く広いので、この先、何がどう変わるかは正直分かりにくいです。2~3年前頃に、業界ではもうGPTは話題になり始めていました。僕の持つ市場インテリジェンス部隊でDiffusion Model(拡散モデル)は衝撃だねと話をしていたところ、実際にMidjourney(画像生成AI)が出て、少しあとにChatGPTが出てきて話題になったのがちょうど1〜2年前の話。ビッグデータからはじまり、今の生成AIブームに至るまで激変です。たった10年で起きたということをにわかには信じられません。
「データ×AIの力で再度人間が解き放たれる時代がくる」と言い続けてきた僕の想像すら超えるレベルでした。今や自動走行車もレベル3で普通に走りはじめていますからね。ただ、データとAIは表裏一体構造ですし、今後は以前からさまざまなところでお話している通り、AI×データの二次的な利用が進むとともに、エコシステムの時代に入ります。そういう意味では、このパラダイムは、真核細胞生物が生まれて一気に多様な生物が生まれ広がっていったように、いろんなものが生まれてくることは予想できる、そういう感じですかね。感覚としては2015~16年にこの話をし始めたときの見立てより、5~10年ぐらい前倒しになっている感じです。
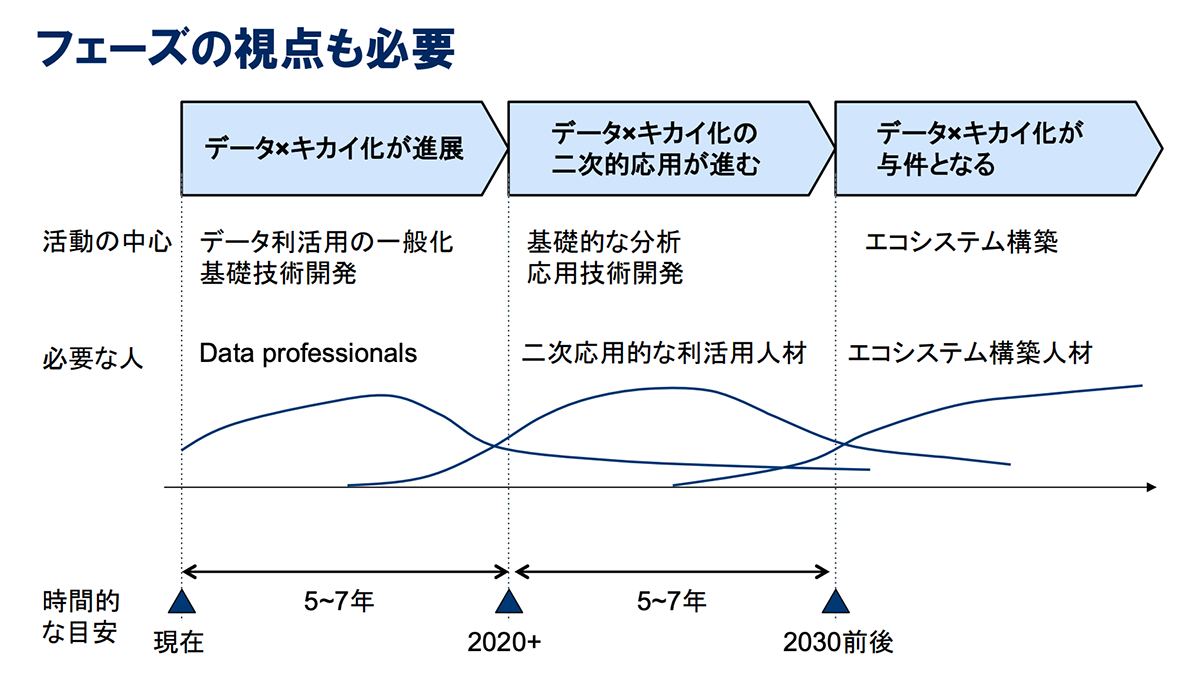
経済産業省 産業構造審議会 新産業構造部会 第5回資料(2016年1月25日)より
※安宅和人『シンニホン』TEDxTokyo 2016でも紹介
また、人間が最もなじみのある知的生産ツールである自然言語(natural language)で計算機と直接やりとりできることの価値は図りしれず、今後の社会はLLM(large language model 大規模言語モデル)を前提として動く可能性が高いと思います。結果的にある種の汎用的なAI、いわゆるAGI(Artificial General Intelligence)の立ち上がりを僕らは日々目撃しているのではないかと思います。


生成AIがビジネス環境にもたらす変化
――生成AIの登場でデータは爆増しているわけですか?
間違いなく、流通するデータは爆増していますが、それは生成AIのためというより、スマホ、スマートウォッチ含めセンサーの数が激増していることと、CGM(Consumer Generated Media)的なプラットフォームが繁栄しているからです。ただ、すでに傾向がありますが生成AIの力によってコンテンツの数もさらに爆増する流れであることも確実です。僕ら、人間の消費能力をはるかに超えてこれらがコンテンツ、そしてデータを生み出していくというのがいま起きていることだと思います。
一方で、AIの訓練に必要なデータは枯渇もし始めつつあります。ウェブからスクレイプ(※1)できない大量のデータを持つ会社の方から、AI的な技術PF側からのアプローチが随分と強まっていると最近聞きます。
※1:スクレイプ:ソフトウェアで処理しやすい形に整形したり、必要な部分を抽出したりすることをスクレイプする、スクレイピングと呼ぶ。
ディープラーニングを組み込んだLLMをはじめ、いろんな数理ベースのモデルがありますが、随分と変数量が多い。最大級の場合、すでに兆単位のパラメーター数に突入しつつある。昔学んだ方程式を思い出してほしいのですが、変数が増えると、変数決定のために必要なデータ量が増えます。モデルが巨大化すれば、当然データは不足してくる。1つのデータをずっと増やして使う技法などは発達してきていますが、それでもデータは不足気味なのではないかと思います。
――信頼性、品質など、私たちが認識しておくべき課題について教えてください。

第一に、現在の生成AIには人間には識別不可能なレベルの真実じゃない情報が混ざってくる問題があります。一つの原因はディープフェイクのような本人すら本物かどうか識別困難な画像、映像、声が技術的にいくらでも生み出しうるということであり、もう一つの原因はハルシネーション(幻覚)と呼ばれる、事実に基づかない、しばしば非現実的な出力が生成される問題です。LLMのアウトプットの場合、それなりのドメイン知識がないと真偽確認すべきかすらわからないものが多いです。
前者のなぜフェイクなものが無限に生み出されるかということの背景にあるのは、アルゴリズム、計算機、データが組み合わさってできるAIが賢すぎるせいと、人間にはこういうことでいろいろやってみることが好きな「いたずら的な性格」があることの相乗効果だと思います。
第二に、AI/機械学習モデルに食わせている(※2)データは2つの意味で課題があることです。それは正しさと、受容可能かという視点です。今の巨大データの多くはCGM、消費者生成メディアといわれているソーシャル系のデータが多いので、あまり正しくないものがどうしても混ざり、機械学習モデルは識別できないままそれを食べてしまうわけです。
※2:機械学習モデルに学習させるデータを与えることを業界用語で「データを食わせる」、餌を与えるという言葉で「フィード(feed)」という表現を使う
また、たとえばボディーダイバーシティ(body diversity)、ジェンダーニュートラリティ(gender neutrality)みたいな議論は、少なくとも15年、20年前、この社会にはほぼなかった議論です。国に対するパーセプション(認知)もすごい勢いで変わることがあります。古いデータにはデータとしては正しくても、現在の社会では受容できない(= not acceptableな)内容が多く含まれています。このように時代とともにわれわれの価値観が変わるために、受容できるかどうか微妙なもの、NGなものも随分とあるわけです。
食わせているデータは必ずしも正しくないし、アクセプタブルじゃない。ただ、これがリアルデータなのです。ですからこの問題のせいで、吐き出されてくる何かがあまり正しくないとか、社会的に受容できない、という問題が起きる。これは生成AIだからうまれる問題というより、データドリブンに発生している課題です。
第三は、研究上わかっていることとして正しい情報より、正しくないもののほうが圧倒的にバズりやすいということです。わざとバズりやすく作っているから広まりやすい。これはソーシャルそのものが持っている課題です。バズっているもの、いかにもバズりそうなものについては真偽を確認するリテラシーが求められます。
第四は、これらを全部利活用してサイバー攻撃問題が発生してしまう課題です。国同士でやったらテロに近い状態になるのですが、対組織、対何々で起きてきます。
これらの問題は絡み合っていますが、違う問題です。ですから、生成AI系によって現れるもの、食わせるデータの問題で現れるもの、そもそも変なものをまき散らしやすいソーシャルの問題、それらを使った攻撃が起きてしまう問題。少なくともこの4つぐらいは自衛のために、現代の基礎教養として認識しておくべきように思います。
――課題が山積ですね。
ですね。大きな問題であり、われわれプラットフォーマーも課題解決にむけて頑張っています。とはいえAI関連については、変化の多くはむしろ新しい喜びをもたらす、すごい力ですので、これらの課題に留意しつつも、使い倒す気持ちでいろいろやってみるほうが大事かと思います。
これは久しぶりに現れた時代を刷新する系の新技術です。200年ぐらい前に蒸気機関がやってきて、マクスウェルだ、エジソンだと電気が登場し、有機化学の時代がきて、ケミストリー(化学)も肥料やプラスチックなどすごい力をわれわれに与えてくれました。そのあと半導体がきて、原子力は大変な不幸も生み出しましたが、かつてない規模のエネルギーを人類に与えてくれました。
その後、半導体の延長の計算機による情報革命がありましたが、その計算機とアルゴリズム、データの掛け算によって生み出された「AI」の生み出す価値は明らかに計算機のもたらしてきてくれた価値のストレートな延長以上のものです。情報の利活用はもう別フェーズにいく。ロボティクスなども、ここからさらに進化していくでしょう。
人類にとって本当に新しいフェーズだと思いますので、リスクには留意しつつも、ワクワクしたほうが良くないですか? 自分が歳をとったときに、「あの時代、面白かった」とか、「ああいうこともしかけたんだよね」と語れる人と、「目を白黒させていたら50年たっちゃったよ、僕」と言っている人、どっちが楽しいかといったら、絶対、前者でしょう。多少やけどするかもしれないけど、いろいろやってみることが大事だと思います。

AI時代に、ビジネスパーソンに求められるマインド
――ビジネスパーソンは、AIに対してどのようなアプローチが必要ですか?
いくつかおかれている場合を分けて議論しましょう。まずは、人口の大多数を占めるはずの世の中一般(general public)的な人。次に、データ・AI系の業界の人。その中の、さらにデータアナリティクス(data analytics)やデータインサイト(data insight)系のプロがいて、さらにその中に各分野のハイレベルなエキスパートがいると思います。われわれの業界で言うとサイエンティスト(scientist)、アプライドサイエンティスト(applied scientist)、アーキテクト(architect)的なエンジニアといった層です。
大多数を占めるゼネラルパブリックのみなさんは、今起きていることが恐ろしく見えるときもあると思います。注意喚起的にひどいニュースが流れがちですから。でも知っていてほしいのは、マイナスの問題は、全体からすると非常に小さい。ほとんどは平和な世界だということです。
ですから、むしろプラスの変化をもたらしている新しい力や可能性に対してワクワクするべきです。このワクワクマインドはめちゃくちゃ重要。ワクワクなくして、すてきな未来なんか生まれるわけがなくて、ワクワクがまず大事だということです。
また、今回も少し話しましたが、どこかで大きな枠組み的な話を時折聞くといいですね。そんなに難しいわけではありません。中の作る側に入ると唐突に難しくなり、データの利活用という意味でもディープな世界ですが、「大枠はわかる」というマインドが一番大事です。その上で、「じゃあ何ができるかな」と考え、次に仲間と一緒でも良いですし、自分でなにかトライしてみる。こういう、3ステップ的マインドセットが良いのではないでしょうか。ビジネスパーソンのほとんど、9割ぐらいはここにいると思います。業界の人は、詳しいスペシャリストたちが真横にいるわけですから、仲良くなったほうがいいでしょう。

――これからの時代、どういう価値観の変化が起きるでしょうか?
結局「その人がその人である価値」というのは、その人なりに面白い価値を感じるとか、その人なりに訳がわからないことを思い付く、それを人に伝えるといったことが中心になると予想されます。「これは面白い」、「これは面白くない」、「これとこれを組み合わせたらこういうのもできるかもしれない」といったことを考える能力。
そこをどうやって生み出すかというと、その人なりに、「本当に生々しく感じて考えたことのあるものが、どこまで広く深くあるか」、あるいは「どれほど人と違う何かがあるか」というところに驚くほど依存してくると思います。なぜなら自分の肉化したような感覚がないと、人間、ものを考えられないですから。
人から聞いた程度のことで考えるとすごく難しくないですか。だから自分で体験してきたことがより重要になる。「自分なりの生々しい体験」があることが、その人なりにものを考えることの何かにつながると信じるということです。それがないと、たぶんわれわれはキカイに負けてしまうでしょう。
LLMの今の表面的な「賢さ」というのはちょっと尋常ではないです。ロシア文学、日本文学、フランス文学、英文学、それぞれをその元言語で全部解しつつ、多言語でも対応し、量子力学も、宇宙物理学も、世界各国の歴史と他国とのつながりも、相当に高いレベルで問いに対応できるわけで、こんな存在、かつてこの世に現れたことがないわけです。ですから、このような時代において、「われわれは、いったいなんなのか」が問われているわけです。
最近、教育研究者向けのセミナーに登壇したのですが、「答えがわかっていること」に対して「答えを覚える」系の訓練は、本当に価値を失いつつあるとお話しました。でも、「どんなことに関心を持つか」、「どういうことがわかったら面白いか」とか、ある種、意味のある問いを立てる、正しい疑問を持つ力、それを言語にできる力というのは非常に重要になっています。答えや出来栄えを評価する能力も必要ですね。これはうまい、まずい、気持ち良い、気持ちよくない、深い、浅いの世界です。
そこを育てようと思うと、やっぱり自分なりの経験、自分なりに考えた量というのが勝負だと思います。その人がその人であるというのは、価値を味わい、評価できる(appreciateできる)というか、味わえるものがそれなりに広くて深くてユニークであるということのような気がします。

LINEヤフーの強み、勝ち筋
――GAFAMが台頭するなか、LINEヤフーは何を強みとし、どこで勝負していくべきでしょうか?
AIの世界は繰り返しになりますがコンピューティングリソースと、アルゴリズム、訓練データのかけ合わせです。これが3要素なわけで、ここの独自性が勝負の源です。少なくともLINEヤフーは、利用からうまれるデータの広がりと量に関して国内でも相当特別な立ち位置にあると言っていい。しかも、普通の人の生活に寄り添っています。僕自身も社員だからというより、単純に便利で、毎日LINEを使うし、毎日ヤフーのサービスをいろいろ使っています。
つまり「多くの人に役立てる」立ち位置にいるという、すごく面白い場所にいる。OpenAI/MS, Google/DeepMind, Metaなどが繰り広げるLLMのグローバルなデファクトスタンダードを取るゲーム以外にも、いろんなレイヤーの戦いがあります。大切なのは現在の取り組みの延長で多くの人に、どれだけワクワクや新しい変化を届けられるか。新会社のミッションで言われているWOWや!はワクワクのことだと思うし、それを生み出せるかどうかが、未来の社会でわれわれが存在し得るかどうかの背骨だと思います。ペイメントのニーズに合わせて、PayPayを生み出せたのもワクワクの一つですね。
――GAFAMに立ち向かうというよりも、ユーザーに向き合うということですね。
そうですね。ですから、WOWや!という視点で、「この社会が求めているのはなにか?」を考えることが大事で、「データを持っているからこれをどう使おう」と考えないほうがいい。WOWや!を生み出すときに、このリソースや過去の蓄積は「どう生かせるか?」と考えたほうが素直だし、世の中の期待に応えやすいのではないでしょうか。
リソースがあり、愛して使ってくださるユーザーがたくさんいていただけるのは幸せなことですから、WOWと!を届けて、じゃあその次は何? というのを考えて仕掛け、多くの人と一緒に実験する。多くの人というのは、使ってくださるユーザーのみなさまです。使ってくださるみなさまとともに未来をどんどん試して作っていくという感じが大事な気がしますね。
関連リンク
取材日:2023年12月11日
※本記事の内容は取材日時点のものです
- LINEヤフーストーリーについて
- みなさんの日常を、もっと便利でワクワクするものに。
コーポレートブログ「LINEヤフーストーリー」では、「WOW」や「!」を生み出すためのたくさんの挑戦と、その背景にある想いを届けていきます。